
Execute Jupyter Notebook from S3 bucket

Triggering Jupyter Notebook execution from the S3 bucket
Running jupyter notebook from an S3 bucket is a common use case for most of us. Sadly AWS doesn't allow or support any provision for the same out of the box.
Today in this blog I will explain how we can execute a jupyter notebook that is residing in an S3 bucket and the output will be omitted back to the S3 bucket.
We will be able to achieve this by using a third-party package named "papermill"
Papermill - How to execute a notebook using Papermill
papermill is a tool for parameterizing, executing, and analyzing Jupyter Notebooks.
Papermill lets you:
- parameterize notebooks
- execute notebooks
Installation
From the command line:
pip install papermill
For all optional io dependencies, you can specify individual bundles
like s3, or azure -- or use all. To use Black to format parameters you can add as an extra requires ['black'].
pip install papermill[all]
Python Version Support
This library currently supports Python 3.7+ versions. As minor Python versions are officially sunset by the Python org papermill will similarly drop support in the future.
Usage
Parameterizing a Notebook
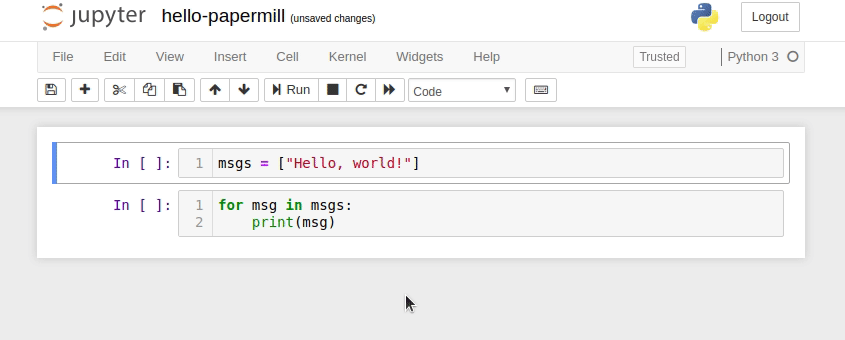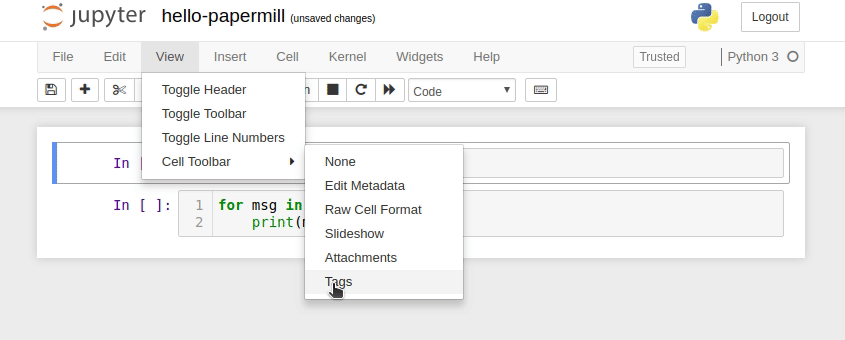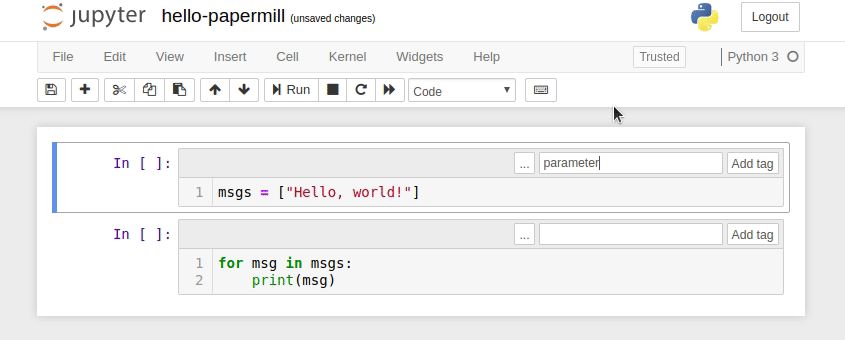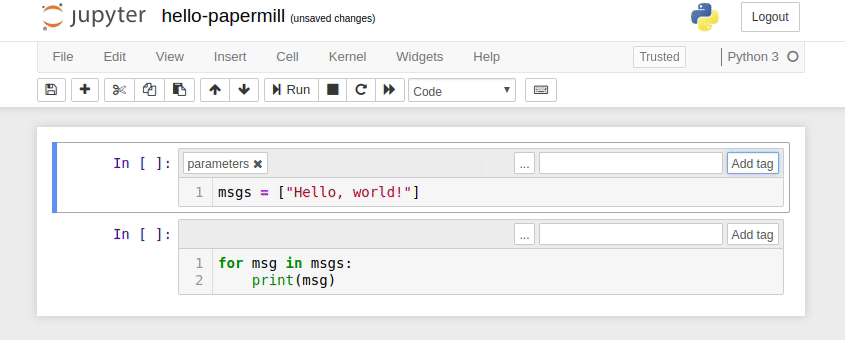
To parameterize your notebook designate a cell with the tag parameters.
Papermill looks for the parameters cell and treats this cell as defaults for the parameters passed in at execution time. Papermill will add a new cell tagged with injected-parameters with input parameters in order to overwrite the values in parameters. If no cell is tagged with parameters the injected cell will be inserted at the top of the notebook.
Additionally, if you rerun notebooks through papermill and it will reuse the injected-parameters cell from the prior run. In this case Papermill will replace the old injected-parameters cell with the new run's inputs.

Executing a Notebook
The two ways to execute the notebook with parameters are: (1) through the Python API and (2) through the command line interface.
Execute via the Python API
import papermill as pm
pm.execute_notebook(
'path/to/input.ipynb',
'path/to/output.ipynb',
parameters = dict(alpha=0.6, ratio=0.1)
)
Papermill on AWS
Now that we know how papermill works and changes to make in jupyter notebook. Let us understand how we can achieve this using AWS.
For paper mill to run on AWS, we will follow these steps
- Create a folder and copy the bash script and code files
- Create a Docker container and push to AWS ECR
- Create a Sagemaker Processing Job passing this docker image and the notebook path
- Create a AWS Lambda which will create the Sagemaker Processing Job and Run the notebook based on Event like S3 trigger or schedule it using Eventbridge
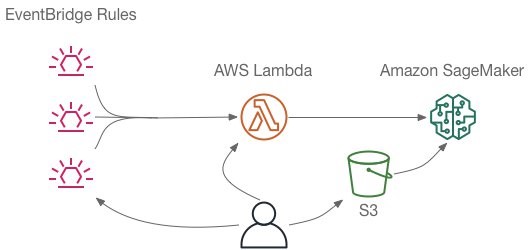
Step 1:
Create the following folder structure and copy the files
.
└── S3_Notebook_Demo/
├── Dockerfile
├── execute.py
├── requirements.txt
├── run_notebook
└── build_and_push.sh
- Dockerfile
FROM public.ecr.aws/docker/library/python:3.8.15-bullseye
ENV JUPYTER_ENABLE_LAB yes
ENV PYTHONUNBUFFERED TRUE
COPY requirements.txt /tmp/requirements.txt
RUN pip install papermill jupyter requests boto3 pip install -r /tmp/requirements.txt
ENV PYTHONUNBUFFERED=TRUE
ENV PATH="/opt/program:${PATH}"
# Set up the program in the image
COPY run_notebook execute.py /opt/program/
RUN chmod +x /opt/program/run_notebook
RUN chmod +x /opt/program/execute.py
ENTRYPOINT ["/bin/bash"]
# because there is a bug where you have to be root to access the directories
USER root
- execute.py
#!/usr/bin/env python
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"). You
# may not use this file except in compliance with the License. A copy of
# the License is located at
#
# http://aws.amazon.com/apache2.0/
#
# or in the "license" file accompanying this file. This file is
# distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
# ANY KIND, either express or implied. See the License for the specific
# language governing permissions and limitations under the License.
from __future__ import print_function
import os
import json
import sys
import traceback
from urllib.parse import urlparse
from urllib.request import urlopen
import boto3
import botocore
import papermill
import shutil
input_var = "PAPERMILL_INPUT"
output_var = "PAPERMILL_OUTPUT"
params_var = "PAPERMILL_PARAMS"
def run_notebook():
try:
notebook = os.environ[input_var]
output_notebook = os.environ[output_var]
params = json.loads(os.environ[params_var])
notebook_dir = "/opt/ml/processing/input"
notebook_file = os.path.basename(notebook)
print("notebook_file", notebook_file)
print("notebook_dir:", notebook_dir)
# If the user specified notebook path in S3, run with that path.
if notebook.startswith("s3://"):
print("Downloading notebook {}".format(notebook))
o = urlparse(notebook)
bucket = o.netloc
key = o.path[1:]
s3 = boto3.resource("s3")
try:
s3.Bucket(bucket).download_file(key, "/tmp/" + notebook_file)
notebook_dir = "/tmp"
except botocore.exceptions.ClientError as e:
if e.response["Error"]["Code"] == "404":
print("The notebook {} does not exist.".format(notebook))
raise
print("Download complete")
os.chdir(notebook_dir)
print("Executing {} with output to {}".format(notebook_file, output_notebook))
print("Notebook params = {}".format(params))
papermill.execute_notebook(
notebook_file, output_notebook, params, kernel_name="python3"
)
print("Execution complete")
except Exception as e:
# Write out an error file. This will be returned as the failureReason in the
# DescribeProcessingJob result.
trc = traceback.format_exc()
# with open(os.path.join(output_path, 'failure'), 'w') as s:
# s.write('Exception during processing: ' + str(e) + '\n' + trc)
# Printing this causes the exception to be in the training job logs, as well.
print("Exception during processing: " + str(e) + "\n" + trc, file=sys.stderr)
# A non-zero exit code causes the training job to be marked as Failed.
# sys.exit(255)
output_notebook = "xyzzy" # Dummy for print, below
if not os.path.exists(output_notebook):
print("No output notebook was generated")
else:
shutil.move(output_notebook, '/opt/ml/processing/output/'+output_notebook)
print("Output was written to {}".format('/opt/ml/processing/output/'+output_notebook))
if __name__ == "__main__":
run_notebook()
requirements.txt
scikit-learn pandas matplotlibrun_notebook.sh
#!/bin/bash
python -u /opt/program/execute.py 2>&1 | stdbuf -o0 tr '\r' '\n'
- build_and_push.sh
#!/usr/bin/env bash
# The argument to this script is the image name. This will be used as the image on the local
# machine and combined with the account and region to form the repository name for ECR.
prog=$0
default_image="python:3.10-slim-bullseye"
function usage {
echo "Usage: $1 [--base <base-image>] <image>"
echo " base: the image to use to build from [default: ${default_image}]"
echo " image: the image to build to. Will be pushed to the matching ECR repo in your account"
}
if [ "$1" == "--base" ]
then
base=$2
if [ "${base}" == "" ]
then
usage ${prog}
exit 1
fi
shift 2
else
base=${default_image}
fi
image=$1
if [ "${image}" == "" ]
then
usage ${prog}
exit 1
fi
echo "Source image ${base}"
echo "Final image ${image}"
# Get the account number associated with the current IAM credentials
account=$(aws sts get-caller-identity --query Account --output text)
if [ $? -ne 0 ]
then
exit 255
fi
# Get the region defined in the current configuration (default to us-west-2 if none defined)
region=$(aws configure get region)
region=${region:-us-west-2}
echo "Region ${region}"
fullname="${account}.dkr.ecr.${region}.amazonaws.com/${image}:latest"
# If the repository doesn't exist in ECR, create it.
aws ecr describe-repositories --repository-names "${image}" > /dev/null 2>&1
if [ $? -ne 0 ]
then
aws ecr create-repository --repository-name "${image}" > /dev/null
if [ $? -ne 0 ]
then
exit 255
fi
fi
# Docker login has changed in aws-cli version 2. We support both flavors.
AWS_CLI_MAJOR_VERSION=$(aws --version | sed 's%^aws-cli/\([0-9]*\)\..*$%\1%')
if [ "${AWS_CLI_MAJOR_VERSION}" == "1" ]
then
# Get the login command from ECR and execute it directly
$(aws ecr get-login --region ${region} --no-include-email)
else
aws ecr get-login-password --region ${region} | docker login --username AWS --password-stdin ${account}.dkr.ecr.${region}.amazonaws.com
fi
# Build the docker image locally with the image name and then push it to ECR
# with the full name.
docker build -t ${image} --build-arg BASE_IMAGE=${base} .
docker tag ${image} ${fullname}
docker push ${fullname}
Step 2 - Build the docker image and push it to ECR (Run these commands in Sagemaker Notebook / Studio)
- Install sagemaker-image package
pip install sagemaker-studio-image-build
import os
os.chdir('/root/Demo')
- build the docker image using sm-docker command
!sm-docker build . --bucket <s3 bucket name>
- Run the Sagemaker Processing Job
import sagemaker
from sagemaker.processing import ProcessingInput, ProcessingOutput, Processor
session = sagemaker.Session(default_bucket= "<s3 bucket name>")
role = sagemaker.get_execution_role()
uploader = sagemaker.s3.S3Uploader()
uploader.upload("Hello_world.ipynb", "s3://<s3 bucket name>/Hello_world.ipynb", sagemaker_session=session)
papermill_processor = Processor(
role = role,
image_uri="<image uri from previous step>",
instance_count=1,
instance_type="ml.m5.large",
sagemaker_session=session,
entrypoint=['/opt/program/execute.py'],
base_job_name="papermill",
env={
"PAPERMILL_INPUT": "Hello_world.ipynb",
"PAPERMILL_OUTPUT": "Hello_world.ipynb.output",
"AWS_DEFAULT_REGION": "us-west-2",
"PAPERMILL_PARAMS": "{}",
"PAPERMILL_NOTEBOOK_NAME": "Hello_world.ipynb"
}
)
papermill_processor.run(
inputs=[
ProcessingInput(input_name="notebook", source="s3://<s3 bucket name>/Hello_world.ipynb", destination="/opt/ml/processing/input")
],
outputs=[
ProcessingOutput(output_name="result", source="/opt/ml/processing/output/", destination="s3://<s3 bucket name>/output")
]
)
Step 3 : Create AWS Lambda and run the notebook from Lambda
- lambda_function.py
import boto3
import time
import re
def lambda_handler(event, context):
#### CHANGE VALUES HERE #####
nb_name="Dummy.ipynb"
s3_input_path_notebook = "s3://<s3 bucket name>/codefiles/Dummy.ipynb"
s3_output_path = "s3://<s3 bucket name>/output"
arn = "<arn>"
################################
timestamp = time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
nb_name="Dummy.ipynb"
job_name = (
("papermill-" + re.sub(r"[^-a-zA-Z0-9]", "-", nb_name))[: 62 - len(timestamp)]
+ "-"
+ timestamp
)
print(job_name)
api_args = {
"ProcessingInputs": [
{
"InputName": "notebook",
"S3Input": {
"S3Uri": s3_input_path_notebook,
"LocalPath": "/opt/ml/processing/input",
"S3DataType": "S3Prefix",
"S3InputMode": "File",
"S3DataDistributionType": "FullyReplicated",
},
},
{
"InputName": "data",
"S3Input": {
"S3Uri": "s3://<s3 bucket name>/codefiles/data",
"LocalPath": "/opt/ml/processing/input/data",
"S3DataType": "S3Prefix",
"S3InputMode": "File",
"S3DataDistributionType": "FullyReplicated",
},
},
],
"ProcessingOutputConfig": {
"Outputs": [
{
"OutputName": "/opt/ml/processing/output/",
"S3Output": {
"S3Uri": s3_output_path,
"LocalPath": "/opt/ml/processing/output",
"S3UploadMode": "EndOfJob",
},
},
],
},
"ProcessingJobName": job_name,
"ProcessingResources": {
"ClusterConfig": {
"InstanceCount": 1,
"InstanceType": "ml.t3.large",
"VolumeSizeInGB": 5,
}
},
"AppSpecification": {
"ImageUri": "<ecr docker uri>",
"ContainerArguments": [
"run_notebook",
],
},
"RoleArn":arn,
"Environment": {
"PAPERMILL_INPUT": str(nb_name),
"PAPERMILL_OUTPUT": "output_" + str(nb_name),
"AWS_DEFAULT_REGION": "us-west-2",
"PAPERMILL_PARAMS": "{}",
"PAPERMILL_NOTEBOOK_NAME": str(nb_name),
}
}
client = boto3.client("sagemaker")
result = client.create_processing_job(**api_args)
return result
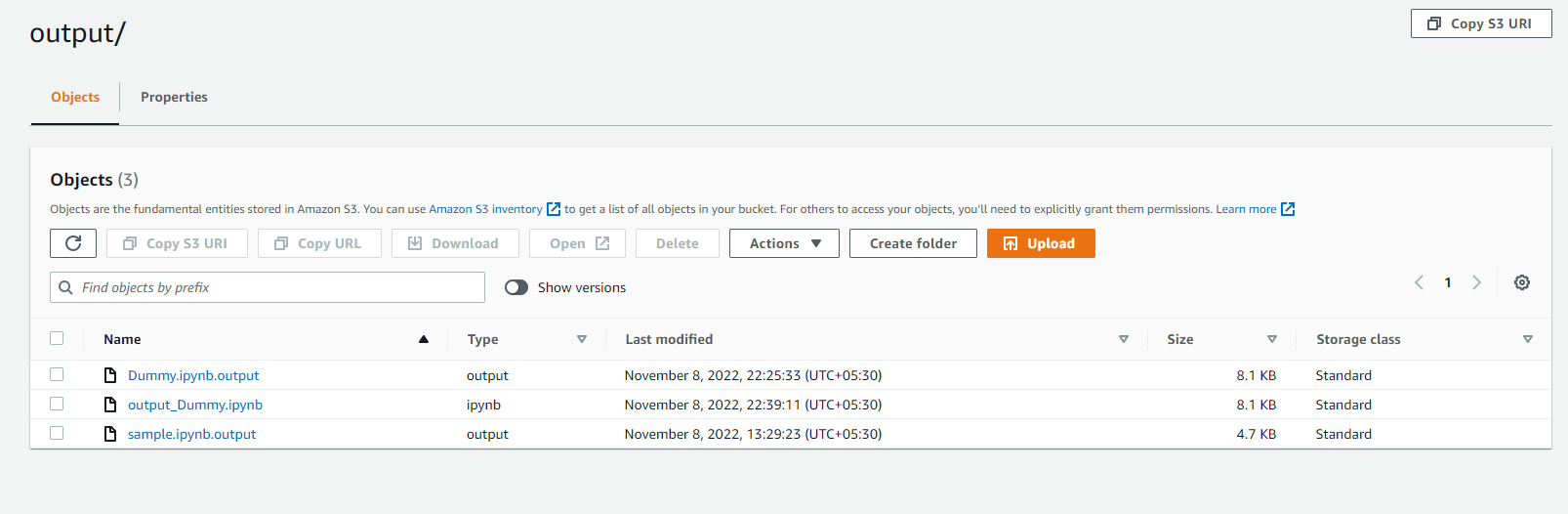
Step 4 : See the ouput notebook in S3 bucket
Appendix
https://papermill.readthedocs.io/en/latest/
https://github.com/nteract/papermill
https://aws.amazon.com/blogs/machine-learning/scheduling-jupyter-notebooks-on-sagemaker-ephemeral-instances/


